Paper link: https://arxiv.org/abs/2106.09685
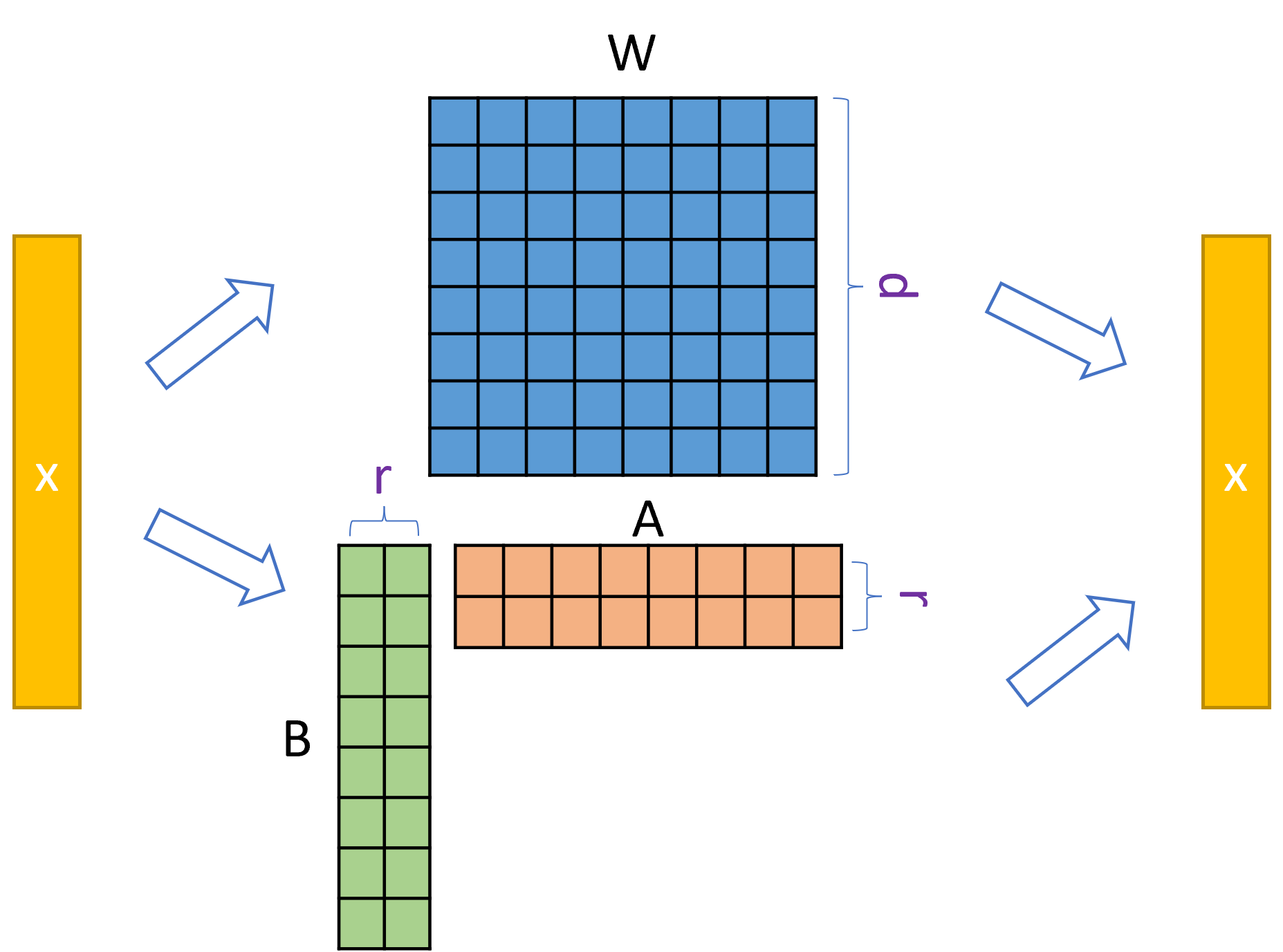
Instead of updating the pre-trained model weights $W_0$ directly, low-rank decomposition matrices added $W_0 + BA$ where $B,A \in R^{d \times r}$ and only $BA$ is finetuned keeping $W_0$ is frozen. After the training, they can be added to get final model.
Advantages
- Large pre-trained model weights are not changed during fine-tuning.
- Inference is the same, $Wx = W_0x + BAx = (W_0+BA)x$
- It is efficient and have small training footprint (Only $BA$ matrices are trained)
- Swapping the models in deployment is fast. $W = (W - BA) + B^\prime A^\prime$
Detailed notes
When adopting LLMs into downstream tasks, they are fine-tuned to learn those tasks. If we fine-tune entire network, it will have huge training and storage costs and each task will require separate model.
The goal is to use small number of parameters when adopting to new tasks. The hypothesis is that the updates to the network during fine-tuning have low “intrinsic rank”. So we can limit the weight updates to the low-rank decomposition $W_0 + \Delta W = W_0 + BA$, where $B, A \in R^{d\times r}, r«min(d,k)$ If the $r=d$ then it represents the full model update so it can recover full training in theory.
For multiple tasks during inference, multiple $(BA)_t$ can be swapped for each task $t$ while keeping the large $W_0$ in memory. For reference $BA$ has $2d$ number of parameters while $W_0$ has $d^2$.