Test-time adaptation
Test-time adaptation is one of the emerging topics in tackling distribution shift in model deployment. Typically, the lifecycle of the model deployment includes followings:
- (Pre)-Training the model on the training dataset offline.
- Deploying the model in real world
- After getting some more data, further retrain the model
- Repeat 2,3 steps
Some of the issues with the above steps are:
- The environment might change during the deployment period, so the model might lose its performance over time. For example, model trained on the images of streets in clear weather will not work as well in fog or snow.
- Retraining the model might require access to the original dataset, which we may have access to. E.g. ViT model trained on JFT-300M
- Even if we only “adapt” the model using the acquired data, we still need to label them for training.
Test time adaptation (TTA) techniques adapt the source model to the distribution of test data, during the testing phase. It will not require access to the source training data and only updates the model using the unlabeled test data.
Also the test data is given in a stream, so we won’t even have access to the entire test dataset. Only the current batch of examples are used for adaptation. This actually matches the real-world deployment case, where the models lifetime includes different test distributions over time.
Most TTA techniques fall into one of the three categories:
- Normalization based methods: (Only updating the parameters or statistics of the BatchNorm layer)
- Entropy minimization: fine-tunes the model by minimizing the prediction entropy of the model
- Prototype-based methods: Modifies the linear classifier so that it maps the input to the embedding space and trains it using the protype representations of each class for prediction.
ActMAD: Activation Matching to Align Distributions for Test-Time-Training
The problem with most of the existing methods is they have constraints on the type of the model and task. For example, normalization based methods mostly work on models with BatchNorm layers. Other methods use some kind of classification based loss for adapting the model.
Proposed solution
ActMAD paper proposes a versatile TTA method which works on any model or task regardless of their design structure. It works by aligning the distribution of individual features across the network. Previous feature alignment techniques used the distribution feature maps as a group. ActMAD takes each individual feature vector and aligns it with the source model. Since the features have position awareness, it allows the network to adapt in fine-grained detail depending on the location of the object in interest. For example, roads are usually on the bottom of the image so the features on the bottom have different distribution than the feature on the top.
Feature alignment/activation matching
During the test phase we keep the original source model $\theta^*$ and adapt our model $\theta$ by taking the statistics of the activation outputs after the normalization layer.
Let say the activation layer $l$ ’s output is $a_l = norm(conv(a_{l-1}))$. Its mean and variances can be calculated across the test batch. We pre-compute the source models activation statistics on the training dataset and have $\hat{\mu_l}$ and $\hat{\sigma_l}$ for each layer. In test time we compute the loss at layer $l$ as:
$$ \begin{equation} L_l(\theta) = |\mu_l - \hat{\mu}_l| + |\sigma^2_l - \hat{\sigma}^2_l| \end{equation}$$
Overall loss is simply the sum of all losses across the layers.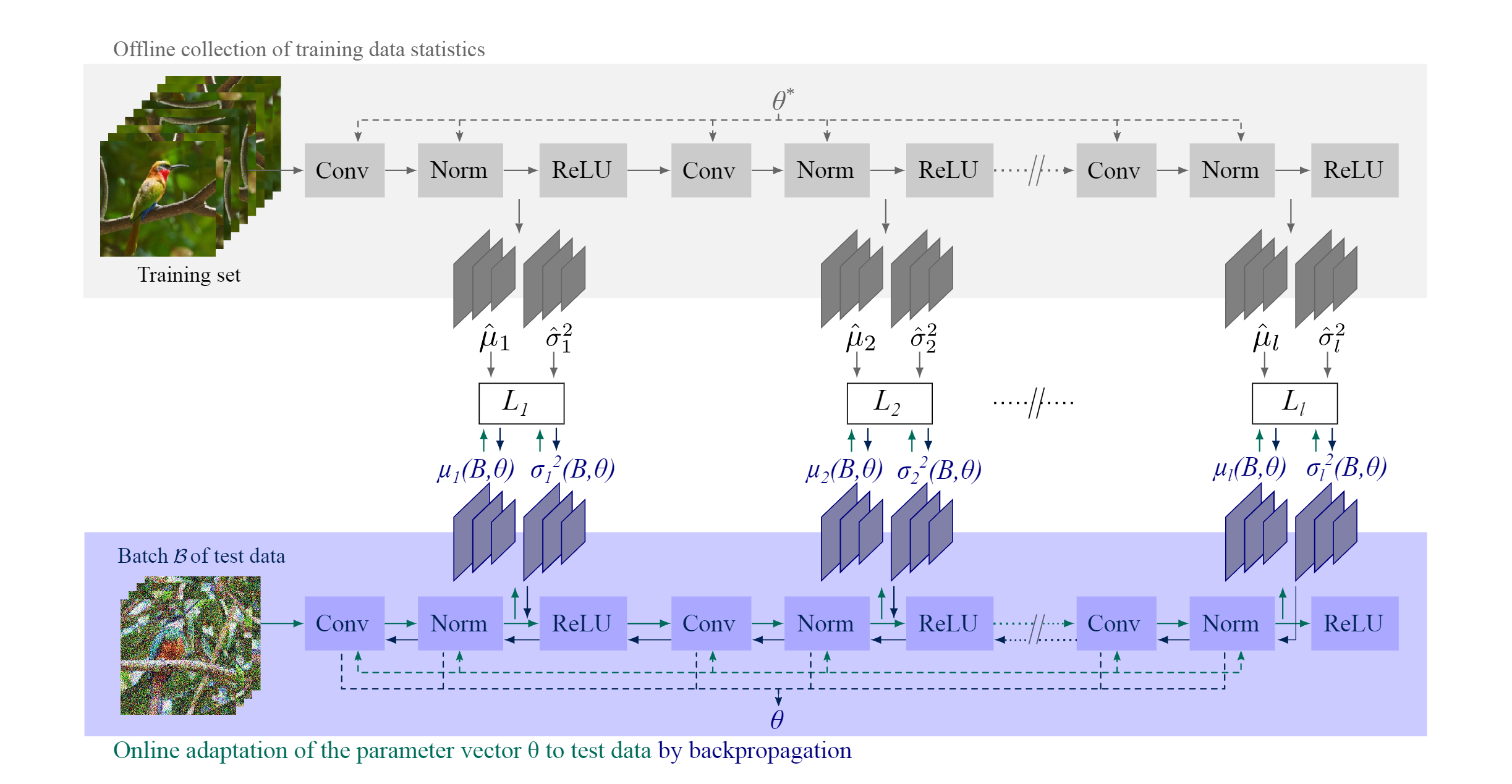
Experimental results
The performance gain of ActMAD is the most significant in KITTI dataset (~10 percent). It is likely because KITTI is constructed from the road images which is more structured that CIFAR or ImageNet. Also the proposed method can be combined with other entropy-based methods.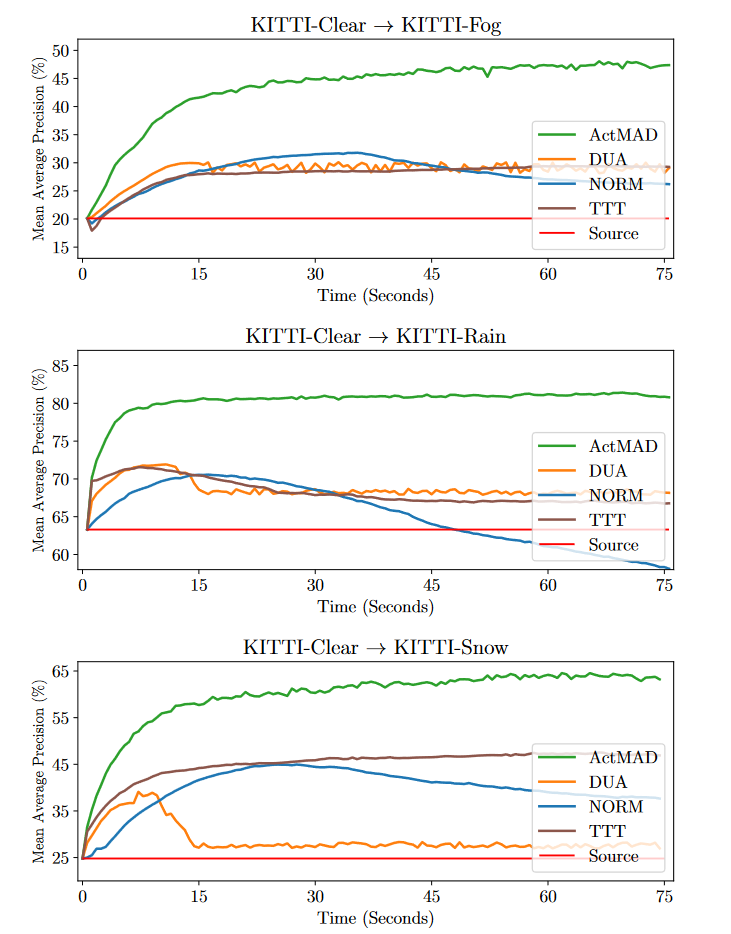
One of the main advantages is it works in object detection and image segmentation tasks with any model, which most of the TTA methods do not consider. Usual datasets for comparison in TTA being CIFAR, ImageNet corruption or other classification tasks.
Conclusion
The proposed method takes different approach in TTA by being fully compatible with any task or architecture. It is especially great in data with location dependent structures: road images, selfies etc. One drawback is it requires the statistics of the activations from the source data which may not be available.