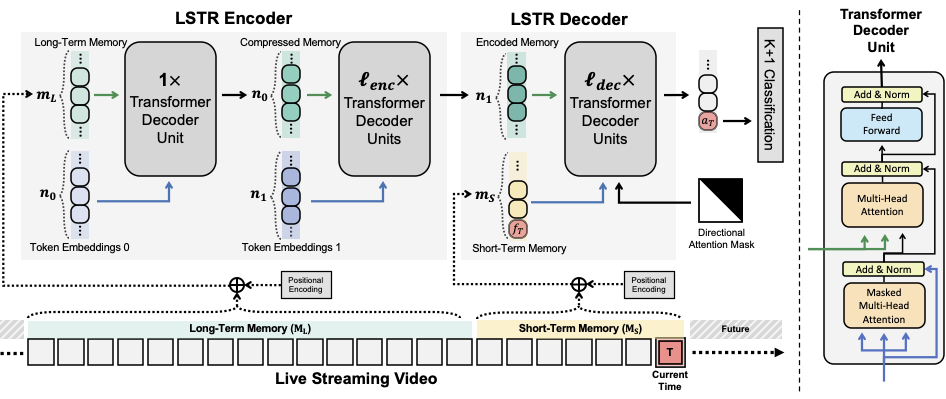
Project Overview
In this project, I significantly improved the Long Short-Term Transformer (LSTR) model for online action detection in video streams. My work focused on enhancing feature extraction, optimizing the transformer architecture, and improving the overall model performance and efficiency.
Key Achievements
- Accuracy Boost: Increased long sequence prediction accuracy from 84% to 94%, a 10% improvement over the original LSTR model.
- Efficiency Gain: Improved optical flow estimation model speed by 70% through optimization and TensorRT compilation.
Technical Approach
1. Feature Extraction Enhancement
- Analyzed and refined the feature extraction pipeline for both RGB and optical flow inputs.
- Implemented advanced preprocessing techniques to improve the quality of extracted features.
- Experimented with various feature fusion strategies to capture complementary information from different modalities.
2. Transformer Architecture Optimization
- Fine-tuned the transformer architecture to better handle long-term dependencies in video sequences.
- Optimized the balance between the long-term and short-term memory components of LSTR.
3. Optical Flow Estimation Optimization
- Profiled the existing optical flow estimation model to identify performance bottlenecks.
- Leveraged TensorRT for model compilation, resulting in significant speed improvements.
Results and Performance
- Accuracy: 94% on long sequence predictions (10% improvement)
- Speed: 70% faster optical flow estimation
- Real-time Performance: Achieved real-time processing on standard GPUs