Project Overview
In this project, I developed the winning solution for the CVPR 2024 Video Captioning Challenge. The task involved creating an captioning model capable of generating accurate and coherent captions for football match video.
Key Achievements
- Developed the top-performing model in the CVPR 2024 Video Captioning Challenge
- Achieved a METEOR score of 27.42 and a BLEU1 score of 44.08
- Successfully combined computer vision and natural language processing techniques
Technical Approach
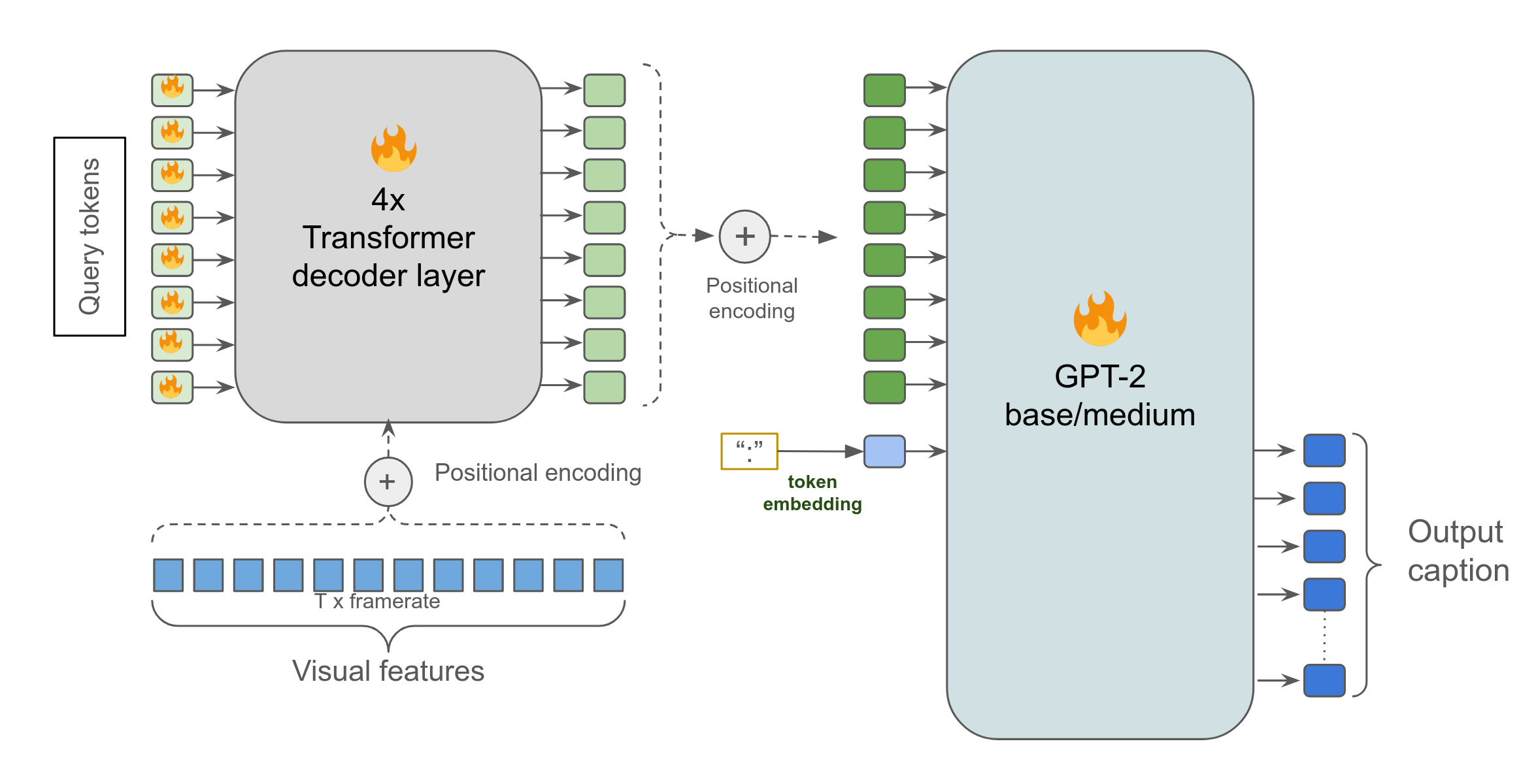
Model Architecture
Our approach was inspired by the BLIP-2 model, consisting of:
- A 4-layer transformer decoder (D=512) with 8 trainable query tokens
- Pre-extracted visual features (window size T=30)
- A pretrained Language Model (LLM) for text generation
Key Components
- Backbone: TransformerDecoder for feature extraction
- LLM: GPT-2 base and GPT-2 medium models
- Tokenizer: GPT-2’s default tokenizer (tiktoken)
My Key Contributions
I improved our action spotter by implementing multi-class classification, resulting in a 0.7-1.4% performance increase.
I fully fine-tuned smaller language models end-to-end with the encoder, solving the issue of frozen pretrained LLMs generating irrelevant captions.
I designed and implemented confidence thresholds to filter out unreliable actions, significantly improving the quality and relevance of our system’s output.
Results and Performance
Our final ensemble model achieved:
- METEOR: 27.42
- BLEU1: 44.08
- BLEU2: 36.55
- ROUGE-L: 41.07
- CiDER: 57.78
Technologies Used
- Python
- PyTorch
- Hugging Face Transformers
- GPT-2
- Custom Transformer architectures